
Artificial Intelligence is kind of a big deal.1 Despite real advances, particularly in medicine, for most clinicians “AI” is at best a shadowy figure, a vaguely defined ethereal mass of bits and bytes that lives in Silicon Valley basements and NYT headlines.
“Bob, the AI is getting hungry.”
“I don’t know, Jane, just throw some AI on it.”
“AI AI AI, I think I’m getting a headache.”
This article is the first of a series meant to demystify AI, aimed at MDs and other clinicians but without too much medical jargon. We begin with definitions (and indefinitions), with examples, of a few of the most popular terms in the lay and technical presses.
There is no generally accepted definition of AI.
This begins a theme that will run throughout this article, best illustrated with an analogy from Humanities 101.
If you pick up a stack of Western humanities textbooks with chronologies of the arts from prehistory to the present, you will likely find a fairly unified canon (try to find a textbook that does not include Michelangelo and Bach, even if it is brand new and socially aware) up until the 1970s or 1980s . At this point, scholarly consensus wanes. It has not had time to mature. As the present day approaches, the selection of important pieces and figures, and even the acknowledgement and naming of new artistic movements (e.g. “post-postmodernism”), becomes idiosyncratic to the specific set of textbook writers.
While the phrase “AI” has been around since 1955, the recent explosion in tools, techniques, and applications has destabilized the term. Everyone uses it in a slightly different way, and opinions vary as to what “counts” as AI. This reality requires a certain mental flexibility, and an acknowledgement that any definition of AI (or any of the other terms discussed below) will be incomplete, biased, and likely to change.
With that in mind, we offer three definitions:

This is the kind of AI that can reason about any kind of problem, without the requirement for explicit programming. In other words, general AI can think flexibly and creatively, much in the same way humans can. General AI has not yet been achieved. Predictions about when it will be achieved range from the next few decades, to the next few centuries, to never. Perceptions of what will happen if it is achieved range from salvific to apocalyptic.

This is the kind of AI that can perform well if the problem is well-defined, but isn’t good for much else. Most AI breakthroughs in recent years are “narrow,” algorithms that can meet or exceed human performance on a specific task. Instead of “thinking, general-purpose wonder-boxes,” current AI successes are more akin to “highly specialised toasters.” Because most AI is narrow, and quite so, when clinicians see any article or headline claiming that “AI beats doctors,” they would be wise to ask questions proposed by radiologist and AI researcher, Dr. Oakden-Rayner: “What, exactly, did the algorithm do, and is that a thing that doctors actually do (or even want to do)?” A more comprehensive rubric for evaluating narrow AI and planning projects is available in the appendix to Brynjolfsson and Mitchell’s practical guide to AI from Science magazine.

We will finish with Kevin Kelly’s flexible and aware definition:
In the past, we would have said only a superintelligent AI could beat a human at Jeopardy! or recognize a billion faces. But once our computers did each of those things, we considered that achievement obviously mechanical and hardly worth the label of true intelligence. We label it “machine learning.” Every achievement in AI redefines that success as “not AI.”
This view of AI takes into account the continual progression of the field, in sync with the progression of humans that produce and use the technology.
Kelly’s quote calls to mind George R.R. Martin’s humorously sobering line,
Fantasy flies on the wings of Icarus, reality on Southwest airlines.
If we flip this quote on its head a bit, we can see that real-life flight is a comprehensible thing, intellectually accessible to any person willing to put in time to learn a little physics and engineering, to the point that it becomes banal. Even for those who know nothing of the math and science, most are unmovably bored during their typical commuter flight, some fast asleep even before the roar of the tarmac gives way to the smooth and steady stream at 30,000 feet.
AI is now, in the minds of many, more akin to Icarus than the 5:15 to Atlanta.
In this series we hope to gain the middle ground: help the reader gain and maintain a sense of possibility and perspective, but also understand the mundane ins-and-outs of day-to-day AI.
A common definition of ML goes something like,
Given enough examples, an algorithm “learns” the relationship between inputs and outputs, that is, how to get from point A to point B, without being told exactly how points A and B are related.
This is reasonable, but incomplete. Each algorithm has its own flavor: assumptions, strengths, weaknesses, uses, and adherents.
The simplest example generalizes well to more complex algorithms:
Imagine an AI agent that is shown point A and point B of multiple cases. If it assumes a linear relationship between input (A) and output (B), which is often a reasonable approach, it can then calculate (“learn”) a line that approximates the trend. After that, all you have to do is give the AI an input, even one it hasn’t seen before, and it will tell you the most likely output. This describes the basic ML algorithm known as Linear Regression.

While linear regression is powerful and should not be underestimated, it depends on the core assumption we outlined, that is, the data are arranged in something approaching a straight line. From linear and logistic regression through high-end algorithms such as gradient-boosting machines (GBMs) and Deep Neural Networks (DNNs), each machine learning algorithm has certain assumptions. A major advantage of many newer algorithms is that their assumptions are far more flexible than the classic regression functions available on high school graphing calculators, but at their core they are still abstracted approximations of the real world, equations defined by humans.
Since the goal of this series is to help the reader try out some machine learning with hands-on coding, we should also note here that in most cases, running a GBM is exactly as easy as running linear regression (LR), if not easier: same number of lines of code, same basic syntax. Most of the time you have to change only one or a few words to switch, for example, from GBM to LR and vice versa. Often, an algorithm such as GBM is actually easier to put into play, because it does not place as many requirements on the type and shape of data it will accept (roughly 80% of a data science job is collecting and whipping data into something palatable to the algorithm). Complexities may come later, when fine-tuning, and interpreting and implementing findings, but those problems are by no means intractable. We’ll get to that in a later post.
Even “unsupervised” machine learning, wherein the algorithm seeks to find relationships in data rather than being told exactly what these relationships should be, is based on iterations of simple rules. Below is an example of an unsupervised learning algorithm called DBSCAN. DBSCAN is meant to automatically detect groupings, for example, gene expression signatures or areas of interest in a radiographic image. It randomly selects data points, applies a simple rule to see what other points are “close enough,” and repeats this over and over to find groups. You have to choose which numbers to use for epsilon: how close points have to be to share a group; and minPts: the minimum number of points needed to count as a group. The makers of this GIF chose 1 and 4, respectively.
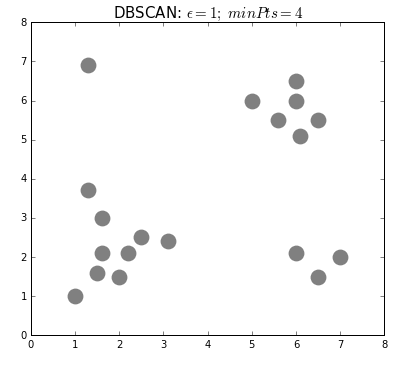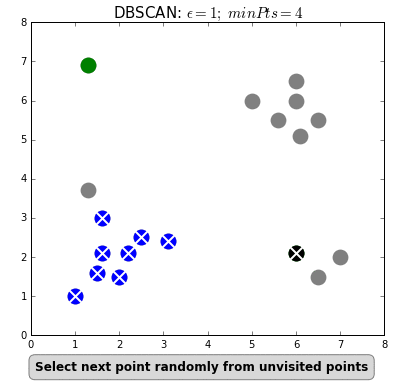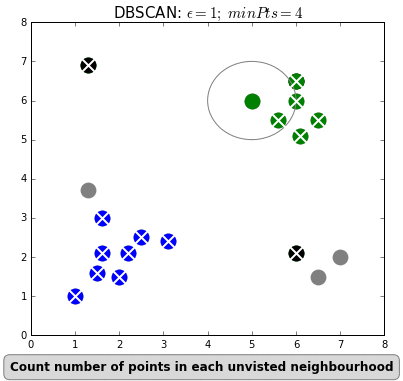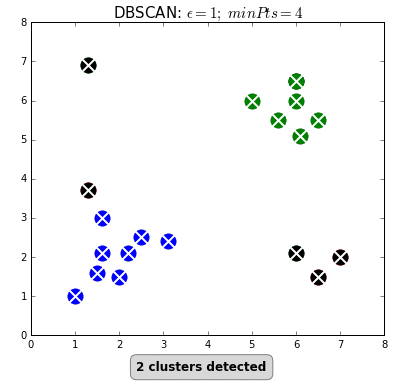
As you can see here, “unsupervised” machine learning is clever and useful, but not exactly “unsupervised.” You have to choose which algorithm to use in the first place, and almost all algorithms have some parameters you have to set yourself, often without knowing exactly which values will be best (would minPts = 3 have been better here, to catch that bottom right group?). It is not so different from selecting a drug and its dosage in a complex case: sometimes you will have clinical trials to help you make that decision, sometimes you have to go with what worked well in the past, and sometimes it’s pure trial-and-error, aided by your clinical acumen and luck.
Lastly, as always, regardless of the elegance of the algorithm, the machine can only take the data we provide. Junk in still equals junk out, even if it goes through an ultraintelligent washing machine.
Deep Learning (DL) is a subset of machine learning, best known for its use in computer vision and language processing. Most DL techniques use the analogy of the human brain. A “neural network” connects discrete “neurons,” individual algorithms that each process a simple bit of information and decide whether it is worth passing to the next neuron. Over time the accumulation of simple decisions yields the ability to process huge amounts of complex data.

For example, the neural network may be able to tell you whether or not something is a hotdog, what you probably meant when you asked Alexa to “play Prince,” or whether the retina shows signs of diabetic retinopathy. These successes in previously intractable problems led researchers and pundits to claim that DL was the breakthrough that would lead to general AI, but, in line with Kevin Kelly’s fluid definition cited above, experience has now tempered these claims with specific concerns and shortcomings.

The best definition of “big data” borders on the tautological:
Data are “big” when they require specialized software to process.
In other words, if you can deal with it easily in Microsoft Excel, your database probably is not big enough to qualify. If you need something fancy like Hadoop or NoSQL, you are probably dealing with big data. Put simply, these applications excel at breaking massive datasets into smaller chunks that are analyzed across many machines and/or in a step-wise fashion, with the results stitched together along the way or at the end.
There is no hard-and-fast cutoff, no magic number of rows on a spreadsheet or bytes in a file, and no single “big data algorithm.” In general, the size of big data is increasing rapidly, especially with such tools as always-on fitness trackers that include a growing number of sensors and can yield troves of data, per person, per day. The major task is to separate the wheat from the chaff, the signal from the noise, and find novel, actionable trends. The larger the data, the more the potential: for finding something meaningful; for drowning in so many meaningless bits and bobs.
AI and related terms have no completely satisfying or accepted definitions.
They are relatively new and constantly evolving.
Flexibility is required2.
Behind all of the technological terms, there are humans with mathematics and computers, creativity and bias, just as there is a human inside the white coat next to the EKG.
Lest you think I’ve lost perspective on what really matters, here’s a comparison of the Google search trends over time for “Artificial Intelligence” and “potato.” Happy Thanksgiving. ↩
A linguistic gem from an early AI researcher is here apropos: “Time flies like an arrow. Fruit flies like a banana.” There are a delightful number of ways to interpret this sentence, especially if you happen to be a computer. How much flexibility is too much? Too little?
The paper with the original Oettinger quote was frustratingly hard to find, as is often the case with classic papers from the middle of the 1900s. So save you the hassle, here’s a PDF. The article starts on p. 166. ↩
{kind=link}